Skip to content
SQL Server According to Bob
Two guys who work on SQL Server
Search:
Home
»
Uncategorized
how-it-works-xevent-string-comparison-performance-tip.html
Category:
Uncategorized
�
Rating
( No ratings yet )
Related articles
Linux
What Am I Working On (RDORR): SQL Server On Linux
To some of you SQL Server On Linux is old news from various announcements
Uncategorized
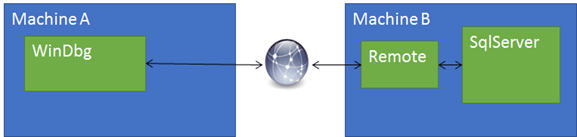
SQL Server on Linux: Debugging ELF and PE Images (dbgbridge)
In my last post I highlighted the marriage of PE and ELF images within