Previous posts have discussed partitioning, for example, a partitioned memory object https://blogs.msdn.microsoft.com/psssql/2011/09/01/sql-server-20082008-r2-on-newer-machines-with-more-than-8-cpus-presented-per-numa-node-may-need-trace-flag-8048/ and how a latch maintains the desired access (exclusive, shared, …) https://blogs.msdn.microsoft.com/psssql/2009/01/28/hot-it-works-sql-server-superlatching-sub-latches/
Quick Refresher Over Partitioned Protection/Locking
- Acquiring shared access requires only the local partition be acquired (lightweight scalability)
- Acquiring exclusive access requires all partitions be acquired (heavier and can be slower)
Shared access blocks exclusive acquire requests. The shared access needs only to acquire on the worker’s local partition. An attempt to acquire exclusive access is blocked by the shared access holders. Conversely to acquire exclusive access the worker must acquire the exclusive access of every partition. The exclusive acquisition path is longer than the shared path because N partitions must be acquired to achieve the exclusive access. Increasing the number of partitions increases the work required to acquire exclusive access. This means that only certain protection paths should use the partitioning approach.
The lock manager (LockMgr) is designed to track partitioned and non-partitioned locks. A handful of lock types (Database, Metadata, LOGIN_STATS, …) are eligible for lock partitioning. Row, Page, Key and other lock types are not eligible for lock partitioning.
For example: When ‘use database’ takes place the session acquires a shared lock on database. Only distinct changes require an exclusive database lock, for example a drop database. Since the exclusive scenarios for a database lock are the tiny percentage of the access patterns the database lock is a perfect candidate to use partitioned locking. I recall when we were tuning the sp_reset_connection (which releases the database lock and acquires it again) command we tested rates in excess of 250,000/sec to ensure the partitioned database lock scaled: https://blogs.msdn.microsoft.com/psssql/2014/03/03/sp_reset_connection-rate-usage-dont-fight-over-the-grapes/
The partitioned memory and latch objects protect in-memory structures for short durations and can be sized according to available memory for SQL Server. The lock manager’s implementation is different because locks protect logical entities for arbitrarily periods of time. For example, a transaction could take out millions of key locks and remain active for minutes or even days. The actual rows need not remain stored in buffer pool, but the rows are transactionaly protected.
The lock manager uses a hash table that is accessed based on the LockResource, where the LockResource is byte array for opaque storage.
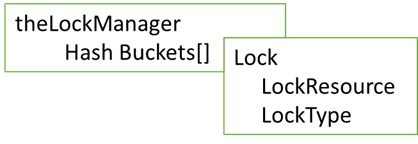
Based on the LockType the LockResource holds the necessary information for the lock, which is formatted nicely in several DMV outputs, including sys.dm_tran_locks.
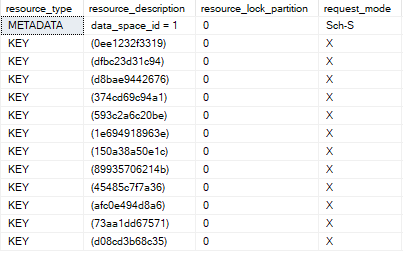
For example, the LockResource bytes maybe used where 4 bytes represent the database id and 8 bytes represent the object id. The opaque bytes are processed by the lock manager to determine the hash bucket location.

To partition this type of lock the partition id is added to the LockResource information. The partition id bytes cause the lock manager to calculate a different hash bucket location. Instead of having a large array structure associated with each lock (most types of locks don’t allow partitioning which would lead to increased and wasted overhead) the LockResource is used to spread out partitioned lock objects.

To acquire a shared lock for this resource the partition id is set to the workers lock partition and the shared acquire is attempted.
To acquire an exclusive lock for this resource the partition id is set to 0 and the lock is acquired for partition 0 in hash bucket, let’s say A. Then the partition id is set to partition 1 and the lock is acquired for partition 1 in hash bucket, let’s say G. The partition setting and acquire activity is repeated until the max partitions supported by the lock manager is reached. Once all partitions have been successfully acquired the EX lock is considered granted and will block any SH attempts.
Note: Partitions are always acquired from 0 to lock manager max to prevent deadlocks.
The lock manager design allows lock types benefiting from partitioning to co-exist with non-partitioned lock types and increased scalability. The example, the Database locks achieving 250,000+ acquires per second tops out around ~80,000/sec without the use of lock partitioning.
Bob Dorr – Principal Software Engineer SQL Server
How It Works Locking

